CharacterSet.decimalDigitsHave you ever needed to check if a string was made up only of digits? How about the presence of punctuation or non-alphanumeric characters? One could use a variety of methods from one of the Formatter classes to NSScanner to even NSPredicate, but the most likely snippet you would've found involved the use of an inverted CharacterSet.
In brief summary, CharacterSet is an Objective-C-bridged Swift class that represents a set of Unicode characters. Its Objective-C counterpart, NSCharacterSet is itself toll-free bridged with Core Foundation's CFCharacterSet. Written in C, CFCharacterSet is quite old, dating back to at least Mac OS 8. The main idea behind CFCharacterSet is to provide an Unicode-aware data structure that aids in the efficient searching of Unicode strings. Both NSString and NSScanner internally use NSCharacterSet for their string searching operations.
CharacterSet can be initialized as an empty set or from a set of characters present within a string, bytes, or the contents of a file. It comes with many conveniently predefined sets (such as the characters allowed in a URL query fragment or alphanumeric characters ) and even allows set algebra such as union, intersection, and exclusive-or.
Using one of CharacterSet's predefined sets feels convenient:
Let’s take a step back and look at the code above. How do you know exactly which characters are included in .decimalDigits?¹ If the snippet above was validating untrusted user input for numerical characters (such as a phone PIN), not knowing exactly which characters belong in CharacterSet.decimalDigits could have substantial security implications as well as creating bugs and other undefined behavior. Let's better understand predefined character sets.
What is in a predefined CharacterSet?
Unfortunately, print() does not work on CharacterSet:
(This log output can be traced back to the original CFCharacterSet. Take a look yourself at line 892 of the earliest publicly available source code for CFCharacterSet !)
Unfortunately, there is no convenient, built-in way to enumerate over the contents of CharacterSet, so let's create our own! In order to do that, we will need some working knowledge of Unicode.
Basic Understanding of Unicode
UTF8 and UTF16
Unicode is a text-encoding standard that became necessary as many non-English speaking parts of the world became connected to the World Wide Web. It defines three structures that are relevant to us: UTF8, UTF16, and UTF32. The number at the end of those three names represent the size of their code units. A code unit are short blocks of bits that, when combined, represent characters. UTF8 has 8-bit code units and UTF16 has 16-bit code units.
UTF8 and UTF16 are considered variable width meaning that one UTF8 character may be represented by up to four 8-bit code units (and two 16-bit code units for UTF16). Consider these two examples of UTF8 characters:
UTF32
Notice that both four 8-bits and two 16-bits both add up to 32-bits. This is entirely by design: UTF32 is a fixed width format into which UTF8 and UTF16 can easily fit without any extra work. All UTF32 characters contain 32 bits, even if it’s not necessary. This makes for an inefficient format, but there is one benefit: it is great for searching because you can iterate over every 32nd bit to get the next character instead of decoding every byte to decode the code point width of that character. This is precisely the reason why NSCharacterSet.characterIsMember(UTF8 or UTF16 or UTF32) internally calls longCharacterIsMember(UTF32) which only accepts a UTF32 character.³
CharacterSet and UTF32
The best way to search the membership of a character within CharacterSet is to get the UTF32 code point for that character and pass it to NSCharacterSet's longCharacterIsMember(). It looks like this:⁶
What’s Inside CharacterSet.decimalDigits?
Let’s go back to our original goal: to see what is inside of CharacterSet.decimalDigits. Here is an example of why it's so important to understand what's inside of it:
What? I did not expect that ᧐᪂᧐ would evaluate as numerical characters. Let’s explore further to understand why.
Printing the Contents of CharacterSet
Armed with how Unicode works for CharacterSet, let's write some code to print the contents of CharacterSet.⁴ Because NSCharacterSet only provides a way to check if an UTF32 character is a member in the set, we will have to loop through every possible UTF32 character and check for their membership in the set:
And if you ran that in Xcode Swift Playgrounds (or here on repl.it ), these are the characters that you would see .⁵
So, What About ᧐᪂᧐?
It turns out that those characters are numerical digits in other writing systems. The ᧐ is the character for “zero” in the New Tai Lue alphabet . The ᪂ is the character for “two” used in the Tai Tham Script .
I encourage you to find other CharacterSets to explore!
Thanks to David Solberg for the inspiration.
Keehun loves to take things apart before putting them back together at LivefrontFootnotes
¹ Apple does provide exact code points of characters in certain sets such as .whitespacesAndNewlines and .newlines, but for most other sets, the documentation only describes the Unicode General Category represented by the set, which may not be particularly helpful (e.g. Apple states that the .alphanumerics set contains “Unicode General Categories L*, M*, and N*”). This website (among others) does provide a sorted list of Unicode General Categories and their characters which I find slow to use.
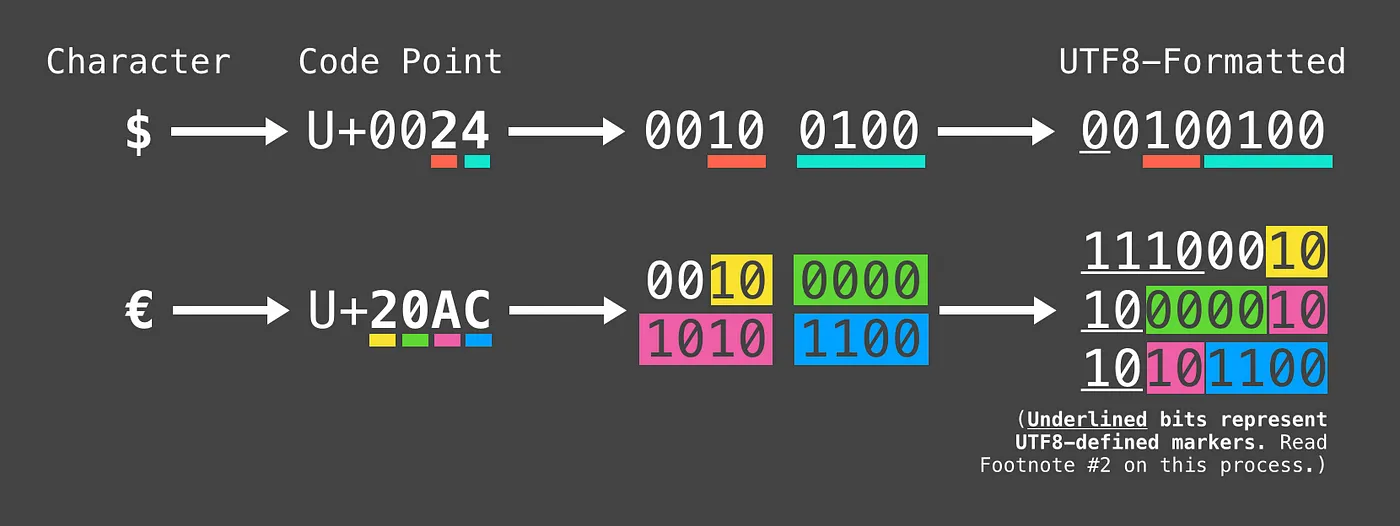
² Here’s how to translate the character’s code point value to UTF8 binary
Knowing the Standardized UTF8 Bit Structure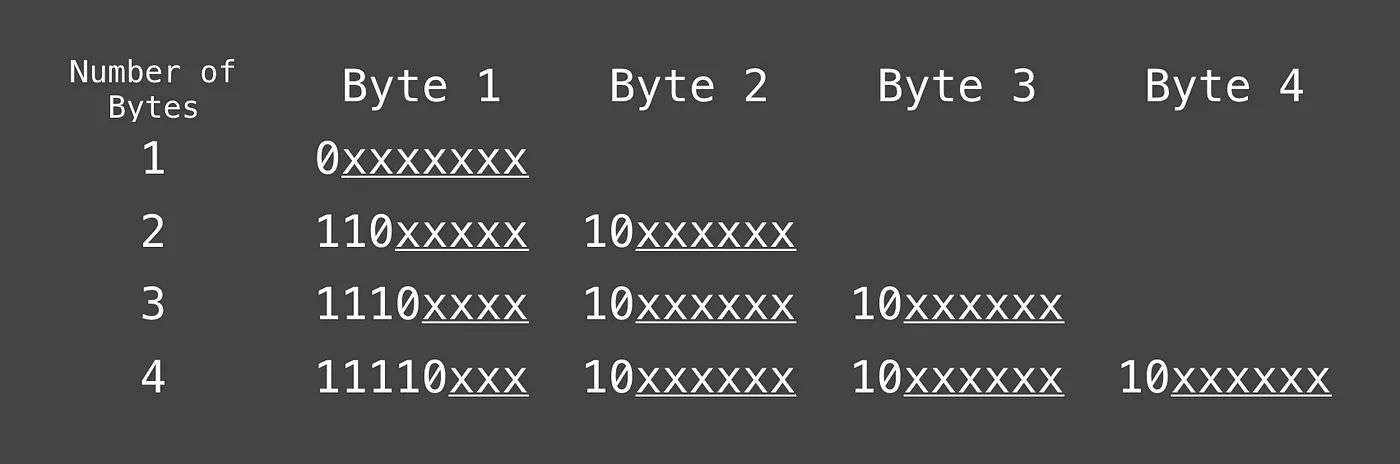
Here’s how to translate the character’s code point value to UTF8 binary: Fill in all the xs in the table above with the binary value for the character.
To figure out how many bytes are needed, consider the length of the character’s code point in binary. 1-byte UTF8 can only accommodate 7 bits (only 7 xs in the table). A 2-byte UTF8 can accommodate 11 bits. 3-bytes can accommodate 16 bits, and a 4-byte UTF8 can accommodate 21 bits.
For the "€" character (U+20AC 10 0000 1010 1100), we need at least 14 bits meaning it will need the 3-byte structure which can accommodate between 12 and 16 bits. The binary digits filled into the UTF8 structure looks like this: 11100010 10000010 10101100 (with the code point in bold).
Notice that if you take away the non-bold binary digits, you get back the original binary for the "€" character!
The first byte in a 3-byte-long UTF8 character always begins with 1110. This is how the UTF8 decoder knows the number of following bytes belong to the same character in the data stream.
³ See line 1655 of CFCharacterSet.c
⁴ I do not recommend using this code for any production apps, or in any apps ever. The provided NSCharacterSet extension is only meant to be used educationally. The code is slow, and some predefined sets are huge (e.g. the .alphanumerics set contains 24,146 characters).
⁵ Again, I don’t recommend using the NSCharacterSet extension in production, ever.
⁶ Thanks to Timur Sharifyanov for the correction of the comment on the 2nd line.
-
Keehun Nam
Software Engineer

