Article
What Barack Obama’s Wardrobe Has in Common With a Good Git History
December 1, 2022
One summer day in the late August heat of 2014, then-President Barack Obama made a decision that would shock the nation: he wore a different suit. The resulting “ tan suit controversy ” dominated a news cycle and spread for a variety of reasons, but ultimately it was triggered by the novelty of the suit itself. Like Steve Jobs’ black turtlenecks and Mark Zuckerberg’s gray shirts, Obama typically stuck with the same blue or gray suits each day.
The common denominator behind this shared behavior is the psychological concept of decision fatigue : that even the smallest decisions we make each day can drain the finite amount of brainpower we have to make decisions and to make them well. A strategy taken by these individuals to preserve this precious resource is to eliminate as many minor decisions as possible: wear the same things, eat the same things, follow the same schedule, and so on. This allows you to focus your mental energy on the decisions that really matter.
So what does this all have to do with everyone’s favorite version control system, git? As with so much in programming, there is no “right” way to structure a git commit or manage the git history of a project; you must simply choose a guiding principle and organize your patterns around it. I personally believe in choosing a strategy that reduces decision fatigue (and “mental fatigue” more broadly) for all the various “consumers” of a commit. I will go into more detail about how to do this below (and feel free to just skip to that numbered list if you’d like) but I think it’s very important to first address why I believe this. And we need to start with who a commit is actually for.
Whose History Is It?
It must be emphasized that over the course of an average project’s entire lifecycle, the number of people viewing a commit that did not write it will far outnumber those that did. These other people will also have the least intimate knowledge of what a commit is actually for and how it is intended to work. As a practical matter, then, building a good git history should really be for them. And, given enough time, even code you wrote yourself can someday appear foreign to you. So keeping a good history can help your future self as well.
Bearing this in mind, it’s worth noting that there are two broad categories of people that will, at some point, view a particular commit:
- Code Reviewers
Those viewing the commit before it is merged into the history through the process of code review. These people are generally known as “code reviewers”. On a good team, everyone will, at some point, be a code reviewer and there may be multiple for each set of new code changes. - Code Detectives
Those viewing the commit after it has been merged. These are typically individuals that are going back through the history to try and understand why something was added or when a bug was introduced. For lack of a better name I will call these people “code detectives” to distinguish them from the folks above.
The job of a code reviewer is roughly to ensure that the code does what it says it does and does not introduce any unintended and undesirable side effects. Crucially, they have an opportunity to make suggestions to improve the code before it becomes history and serve as the first line of defense in preventing mistakes from entering the project’s code base. In order to do these things well, though, they first have to be able to completely understand code that they did not write. Even with the ability to discuss the code with the author, this type of exercise can be very mentally taxing.
Code detectives have all these same challenges in addition to others: they may not always know what they are looking for and even when they find it, they may be lacking vital context for understanding it. Many times they do not even have the benefit of being able to talk with the original author of the code. For this reason, a large part of what a code detective does is to try and infer the intention of existing code without actually being able to ask about it or follow up on their suspicions.
The jobs of these two groups are slightly different but at their core they both involve a series of decisions that must be made, line by line, to answer the ultimate question: what does this code even do? Depending on how the commits are structured by the author, this can either be relatively straightforward or a painful slog with unnecessary roadblocks and red herrings.
Decisions, Decisions
Let’s now consider what kinds of decisions go into understanding a commit. First we need to note that each line of a commit can be categorized as one of two things: an “added” line of code or a “removed” one.
Without any additional context, the following decisions must be made when viewing a single line of “added” code:
- Is this an entirely new line of code?
- If it is not a new line of code, is it an existing line of code that has simply been moved from somewhere else?
- If it is not a new line of code and it has not been moved, is it a trivial modification of an existing line (such as a formatting change) or is it a legitimate logical change?
- If it is either an entirely new line of code or a modification that leads to a logical change, why is it being done? Is it done correctly? Can it be simplified or improved?
Note that the final point is really the “meat” of understanding the commit and the first three points are much more trivial but still entirely necessary decisions that must be made in order to reach this point.
We can see a similar process for each “removed” line of code:
- Is this line being removed entirely?
- If it is not being removed entirely, is it being moved or modified?
- If it is not being removed entirely and it is not just being moved, is it the result of a trivial modification (ex: formatting) or the result of a logical change?
- If it is in fact a logical modification, why is it being modified? Is it being done correctly?
- If the line is being removed entirely, why is it no longer needed?
Once again, the final two points are what really matter.
So this finally brings us back to decision fatigue:
How can we organize commits so that we eliminate these first few trivial choices and allow viewers to focus on the important ones?
You don’t want your team spending their limited brain power and time deciding, for example, that some chunk of code was just moved from one module to another without modification and then miss the coding mistakes present in the actual new code. Multiply this across teams at a big organization and this can add up to a measurable loss of productivity.
So, now that we’ve discussed why I believe we should follow this strategy, let’s finally discuss how I advocate for putting it into practice.
1. Place trivial modifications in their own commits
The simplest and most important thing to do is to separate trivial modifications out into their own commits. Some examples of this include:
- Code formatting changes
- Function / variable / class renames
- Reordering of functions / variables / imports within a class
- Removing unused code
- Moving file locations
When placed in their own commits, these kinds of changes do not require much, if any, investigation into their “correctness”. When mixed with other changes, though, they are a huge source of mental drain, forcing you to find the logical pin in the haystack of code churn.
Consider the following commit mixing trivial changes with non-trivial ones:
Commit message: “Update valid fruits list”
How long did it take you to spot the non-trivial changes? Now see what happens when these two changes are split up into two separate commits:
Commit message: “Update valid fruit list formatting”
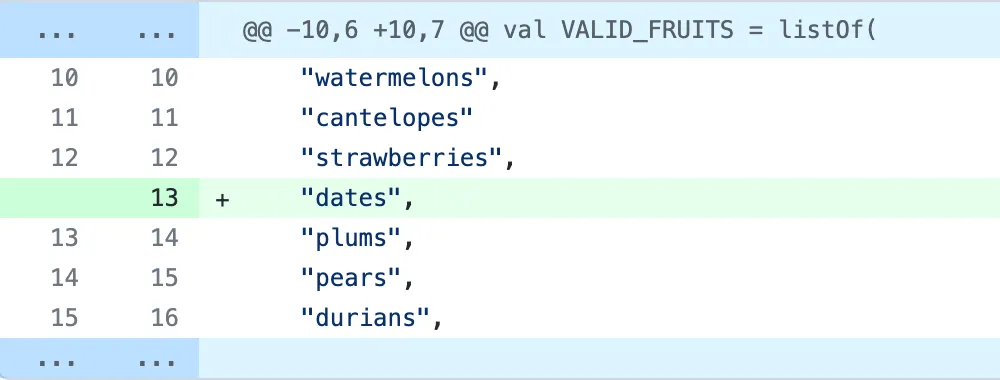
The “formatting only” commit can essentially be ignored and the code additions can be discovered immediately at a glance.
2. Place code refactors in their own commits
Code refactors involve changes to some code’s structure but not its function. Sometimes this is done for its own sake but often it is done out of necessity: in order to build upon existing code it is sometimes necessary to first refactor it and it can then be tempting to do both things at once. Mistakes can be made during a refactor, though, and special care is required when reviewing them. By placing this code in its own commit clearly indicated as a refactor, the reviewer knows to flag any deviation from the existing logical behavior as a possible mistake.
For example, how quickly can you spot the mistake here?
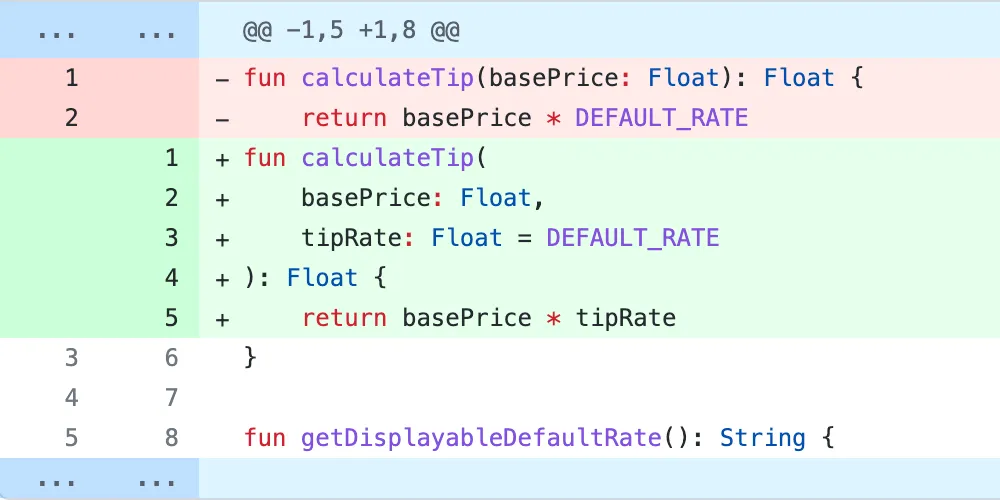
Commit message: “Update tip logic”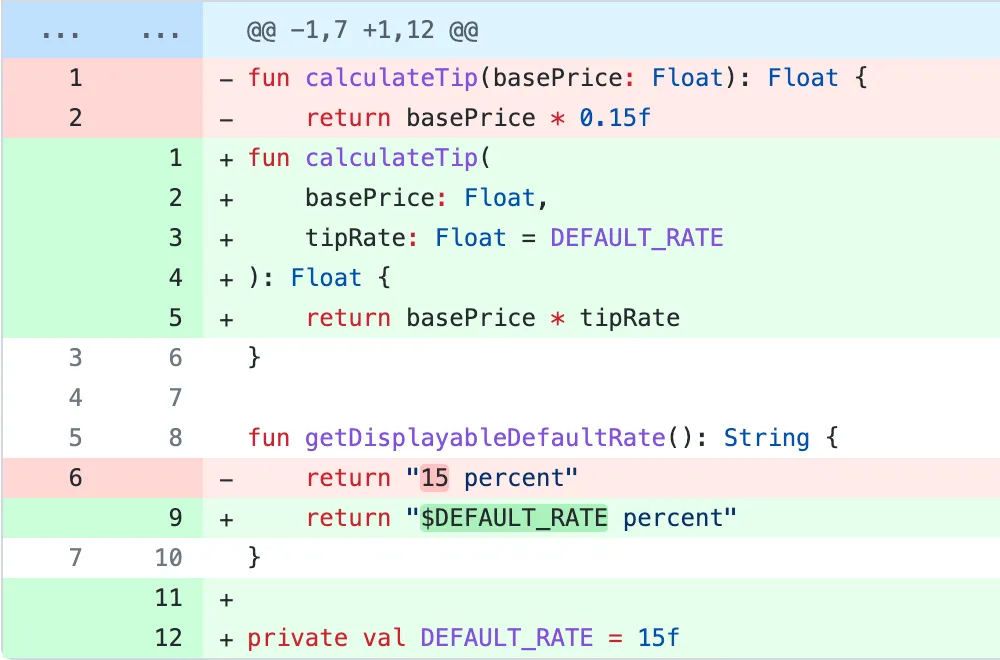
How about now with the refactor split out?
Commit message: “Extract default tip rate”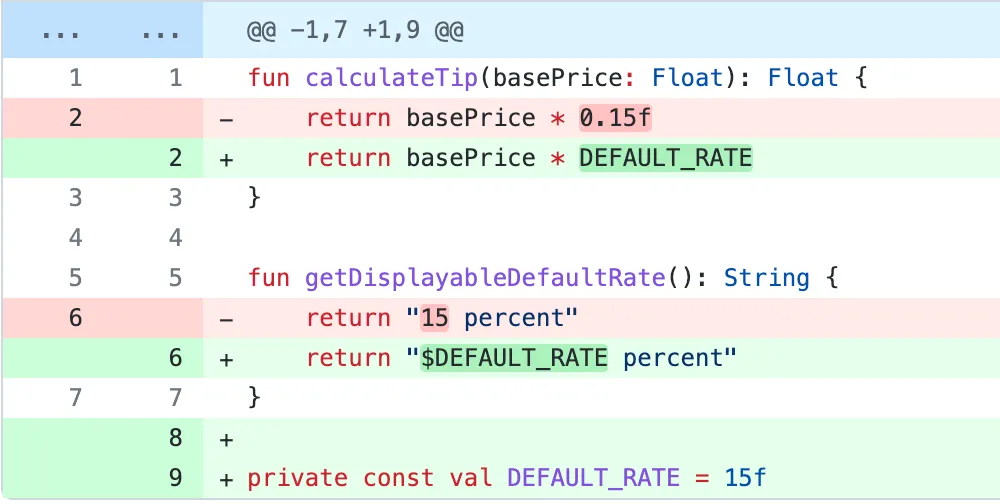
3. Place bug fixes in their own commits
Sometimes in the course of making code changes you notice a bug in the existing code you are seeking to modify or build upon. In the interest of moving forward you may just fix that bug and include it in your otherwise unrelated changes in the same commit. When mixed in this way there are several complications:
- Others viewing this code may not know that there is a bug being fixed.
- Even when it’s known there is a bug fix included, it can be hard to know which code was part of fixing the bug and which was part of the other logical changes.
Either way, the interpretation of the code becomes more difficult to decipher with these changes mixed together. And as there are many ways to fix a bug, the one that allows your current code changes to move forward may not be the solution to the greater problem caused by the bug and this partial fix may just muddy the waters. These fixes deserve consideration on their own.
4. Place separate logical changes in their own commits
After splitting out the above types of changes, you should now be left with a single commit with legitimate, logical changes to add / update / remove functionality. For a small, concise change this is often enough. However, sometimes this one commit adds an entirely new feature (with tests) and clocks in at 1000+ lines (or more). Git will not present these changes in a coherent way and successfully understanding this code would require the reviewer to skip around and keep a large fraction of these lines in memory at once to follow along. Along with the decision fatigue involved in processing each line, stretching your working memory in this way is mentally taxing and ultimately inefficient.
Whenever possible, split up commits based on domains such that each commit independently compiles. This means that the most independent code can be added first, followed by the code that depends on it, and so on. Well-structured code should split up in this way quite naturally, while difficulties found at this stage might hint at larger structural issues like circular dependencies. This exercise may even lead to improvements in the code itself.
5. Merge any review changes into the commits they belong to
After splitting up your work into several clean commits, you may get review feedback that requires you to make changes to code that appears in one or more of them. Some developers will react to this feedback by adding new commits that address these concerns. The commit list in a given PR might start looking like the following:
- <Initial commits>
- Respond to review feedback
- Work
- More work
- Addressing more review feedbackThe first to review this code might find it helpful to see these partial changes but anyone coming late to the party will just end up expending mental energy viewing the original code that is no longer relevant. Therefore, all changes should be merged back into the commits where they belong, as if the code existed that way from the beginning. Interactive rebasing is going to be your best friend here. This will then require you to force-push your feature branch back up. This can be tricky and has some costs but there is no reason to fear it! Reviewers will simply need to reset their local copy of your branch (if they have one), and that’s OK.
The same goes for when a pull request is first opened: each commit should have a purpose and it should not be negated by changes in later commits for all the same reasons mentioned above.
Consider this initial change followed by several “work” commits:
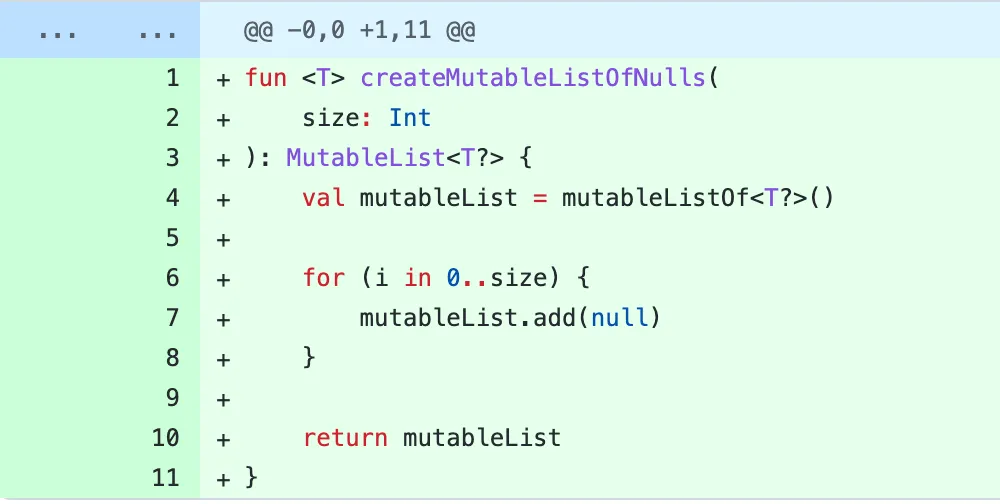
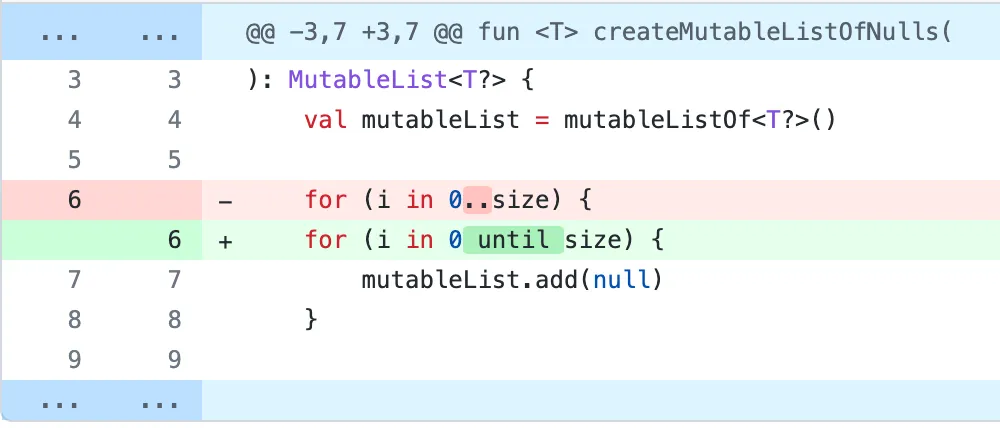
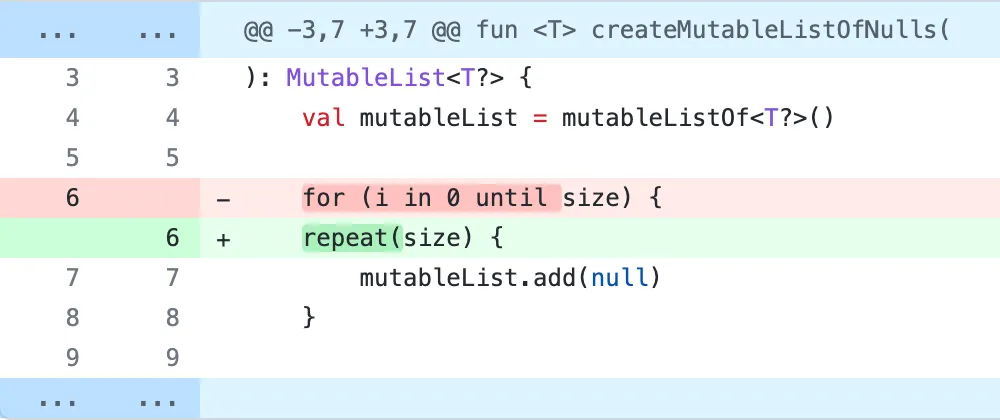
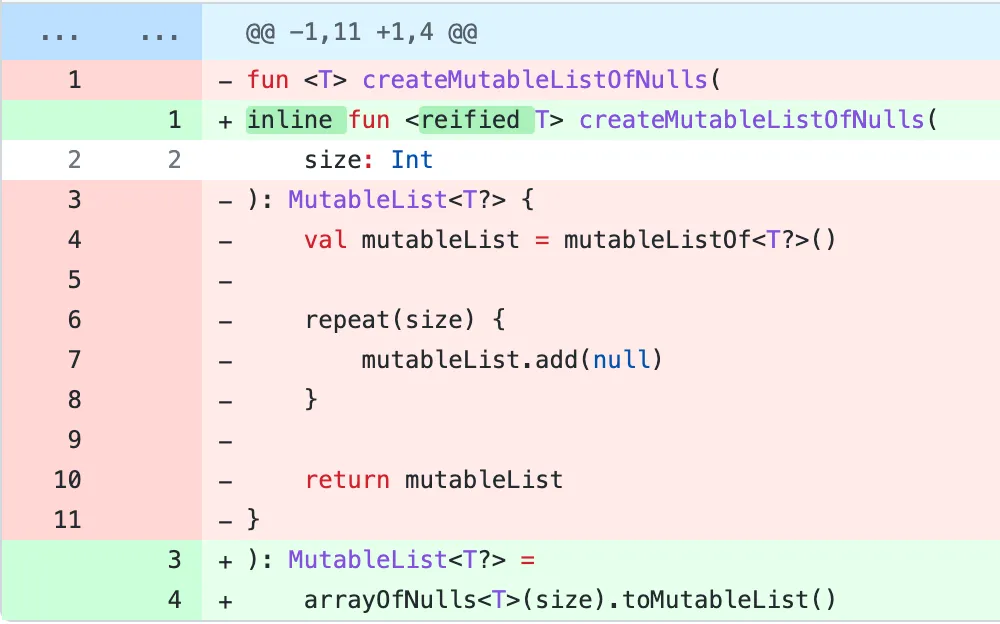
Now imagine you are seeing these changes well into the process (or even years later). Wouldn’t you want to just see the following?
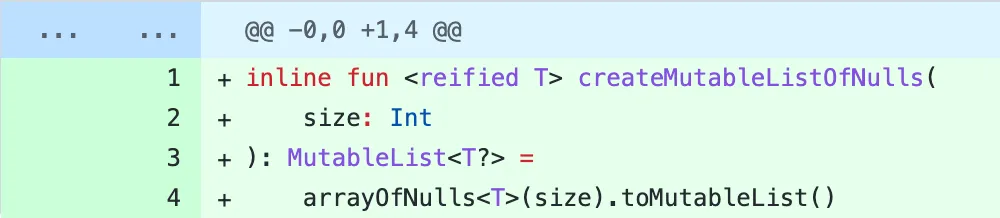
6. Rebase, rebase, rebase!
If a feature branch has existed long enough — either because of the time it takes to add the initial code or because of a lengthy code review process — it can start to conflict with changes made on the main branch it was originally based on. There are now two ways to make the feature branch current:
- Merge the main branch into the feature branch. This will generate a “merge commit” in which all the code changes required to address the conflicts are included. If the feature branch is particularly old, these types of commits may be substantial.
- Rebase the feature branch against the main branch. The end product here is a new set of commits that act as if they were just created based on the updated main branch. Any conflicts will need to be dealt with as part of the rebasing process but all evidence of the original version of the code will be gone.
Whenever possible, you should choose the 2nd option: rebasing. Merge commits like this negate all the work done to sort out commits based on the previous steps because all types of changes can be present in a merge commit. And much like the “work” commits described above, they result in wasted mental energy: those looking at the code try to understand how it works, only to find that substantial changes are made in a completely disorganized merge commit.
If you care about producing a clean history (and you should!), rebasing is the best option here: all changes build off each other in an orderly and linear fashion. You do not need fancy history-viewing tools to understand the relationship between branches.
Consider the following project history that employs merging between branches:
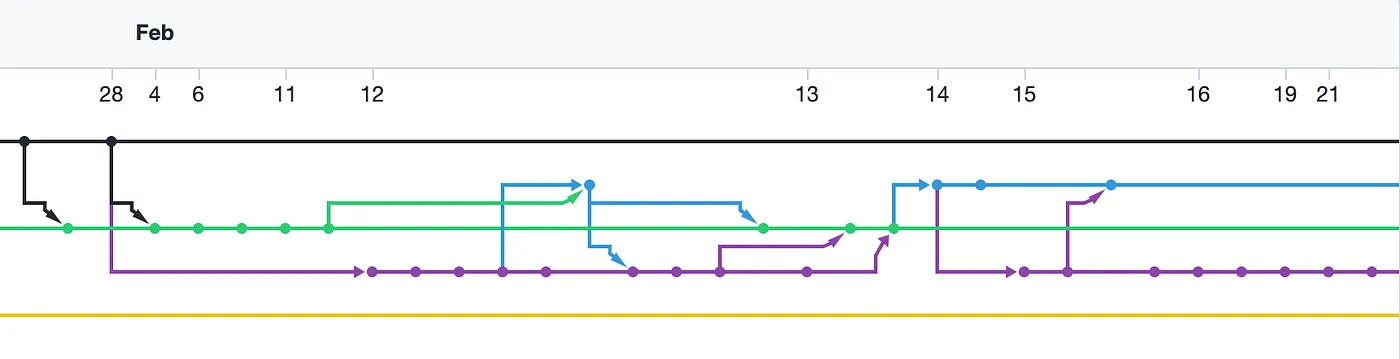
Compare this to a project that rebases all changes and forbids merge commits even when merging features into the main branch :

In the former, the relationships between changes must be plotted, pondered, and deciphered; in the latter, you simply flow forward and backward in time.
Some may argue that it is actually rebasing that destroys history; that you lose the history of changes made to get some code in its final shape before being merged. But this kind of history is rarely useful and is very developer-dependent: one person’s journey may differ from the next, but what matters is seeing a series of commits in the history that reflect the final changes they represent…whatever process it takes to get there. Yes, there are special cases here where merge commits are unavoidable, but they should be the exception. And often the scenarios that cause these (such as long-lived feature branches shared by multiple team members) can be avoided using better work flows (like using feature flags instead of shared feature branches).
Counterarguments
There are certainly arguments that can be made against this approach and I’ve had plenty of discussions with people who disagree with it. These points are not without merit and as I mentioned at the beginning of the article, there is no one “right” way to structure commits. I want to quickly highlight some points I’ve heard and give my thoughts on each.
“Worrying about commit structure so much slows down development.”
This is one of the most common points I’ve heard against this approach. It is certainly true that it will take some extra time for the developer writing the code to carefully consider and split up their changes. However, this is also true of any other kind of additional processes that are meant to safeguard against the inherent weaknesses of prioritizing speed and, in the long-run, it might not save the team as a whole any overall time. For example, the argument that development will be slowed is used by teams that do not write unit tests, but these same teams then need to spend more time fixing broken code and manually testing refactors. And, once a team is in the habit of splitting up their changes in this way, the extra time added is greatly reduced because it just becomes part of the normal development process.
“My project uses tools that do not even allow for trivial formatting changes.”
I agree that this is a great way to minimize the harm that is otherwise caused by formatting-related code churn. As an Android developer, I’m a firm believer in team-wide use of auto-formatters and swear by tools like ktlint . However, I also know firsthand from configuring all these tools that they are not perfect and there are plenty of possible formatting changes that they are totally agnostic about. And, as discussed above, some trivial changes are not simply formatting changes, like reordering code. There are always going to be trivial code changes that can be made and therefore there must be a plan for how best to deal with them.
“Not all git hosting sites allow Pull Requests with multiple commits.”
This is very true! My recommendations are primarily based on using tools like GitHub and GitLab that allow a PR to have as many commits as you’d like, but there are tools such as Gerrit that do not. In this case, just consider each commit as being its own PR. This does introduce even more overhead for the author (and sometimes for the reviewers) but I believe that in the long-run it is worth the effort. There may even be ways to streamline this process and relate these separate PRs to each other, such as using “dependent changes” in Gerrit.
“A single commit ensures that all changes compile and pass tests.”
This too is a very good point. The automated checks that run on git hosting sites typically only run against the entire set of changes, not for each individual commit. If there is a broken commit along the way that is fixed by later changes, there is no way to automatically detect this. You want each commit to be able to stand on its own in case you someday need to go back and test the state of the code at that point to track down bugs, etc. As an understood rule it should be required for each commit in a multi-commit PR to both compile and pass any relevant tests, but there is no way to strictly enforce this (other than to make each commit its own PR). This requires vigilance but is just something that needs to be weighed against the benefits that come with splitting up the code.
“A single commit provides the most context for all the changes.”
This one is an interesting point. While git hosting sites like GitHub allow for comments to be added in bulk to a group of commits as part of a PR description, no such thing exists in git itself. This means that the link between commits added in the same PR is not strictly part of the history. Fortunately, sites like GitHub have features that add a link to the PR that produced a commit when viewing it in isolation:
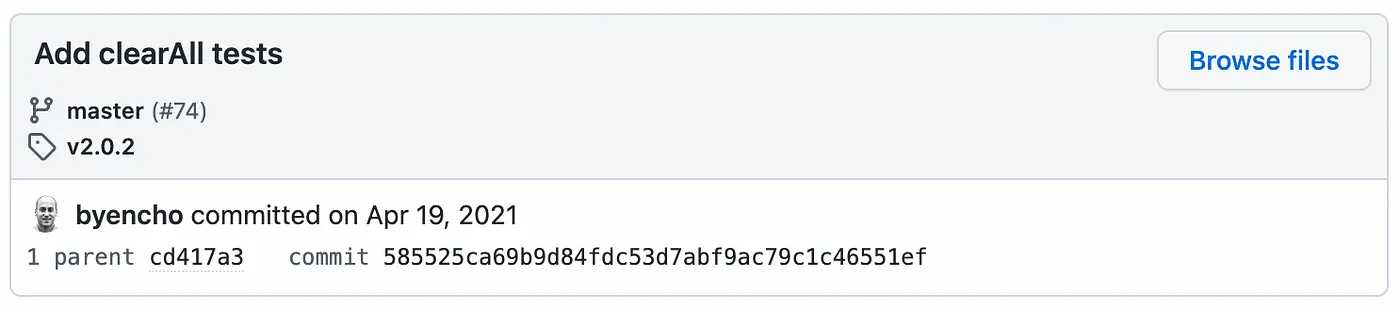
While this is not as helpful as having this link in the git history itself, for many projects this is an adequate way to keep track of the relationship between commits.
Final Thoughts
I hope to have convinced you that splitting code changes into distinct commits of several types has benefits for everyone in the development process:
- It can help the writer improve the structure of the code and better convey the content of the changes.
- It can help code reviewers more quickly review the code and reduce mental fatigue by allowing them to focus their attention on separate, meaningful changes.
- It can help anyone looking back on the code history to find logical changes and bugs more quickly and similarly reduce the mental load that comes with skimming through large amounts of history.
This is a strategy optimized for teams rather than for individuals and I believe it’s in the best interests of the overall health of a project. Developers may come and go, but git history lives on. Best to make the most of it.
Brian works at Livefront , where he’s always trying to make just a little more (git) history.

