Article
Optimism is not assurance.
June 26, 2026
Somewhere along the way “The tests are passing” became an acceptable answer to “is this ready to ship?”. Those are not the same question. Automated tests check what you told them to check, using the conditions you anticipated, against the assumptions you have already made. They cannot notice what they weren’t written to look for.
The tools we have available now are incredible. In this agentic moment, we can create an implementation plan, write the code, and review it all in minutes, and in that excitement, Quality Assurance can start to look like a bottleneck and a relic of a slower era of software development.
I’ve been in those conversations. I’ve also seen what happens when the decision goes the other way.
Tools change. Trends change. The need to actually check your work before shipping it doesn’t.
We’ve always found reasons to skip QA
AI didn’t invent the impulse to cut QA. Product development teams have been finding reasons to skip it for as long as software has existed.
- “We’re moving too fast.”
- “The team knows the codebase well.”
- “We’ll catch issues in prod.”
- “We can’t afford a dedicated QA person right now.”
These aren’t new ideas, and they’re not entirely wrong, either. There are real constraints on small teams, and a dedicated QA function isn’t always realistic. But there’s a difference between acknowledging a constraint and treating it as a feature.
The case for cutting QA rarely arrives as a singular bold decision. It creeps in through a series of individually reasonable ones. And if you look at it through the lens of the Iron Triangle the pattern becomes hard to ignore.
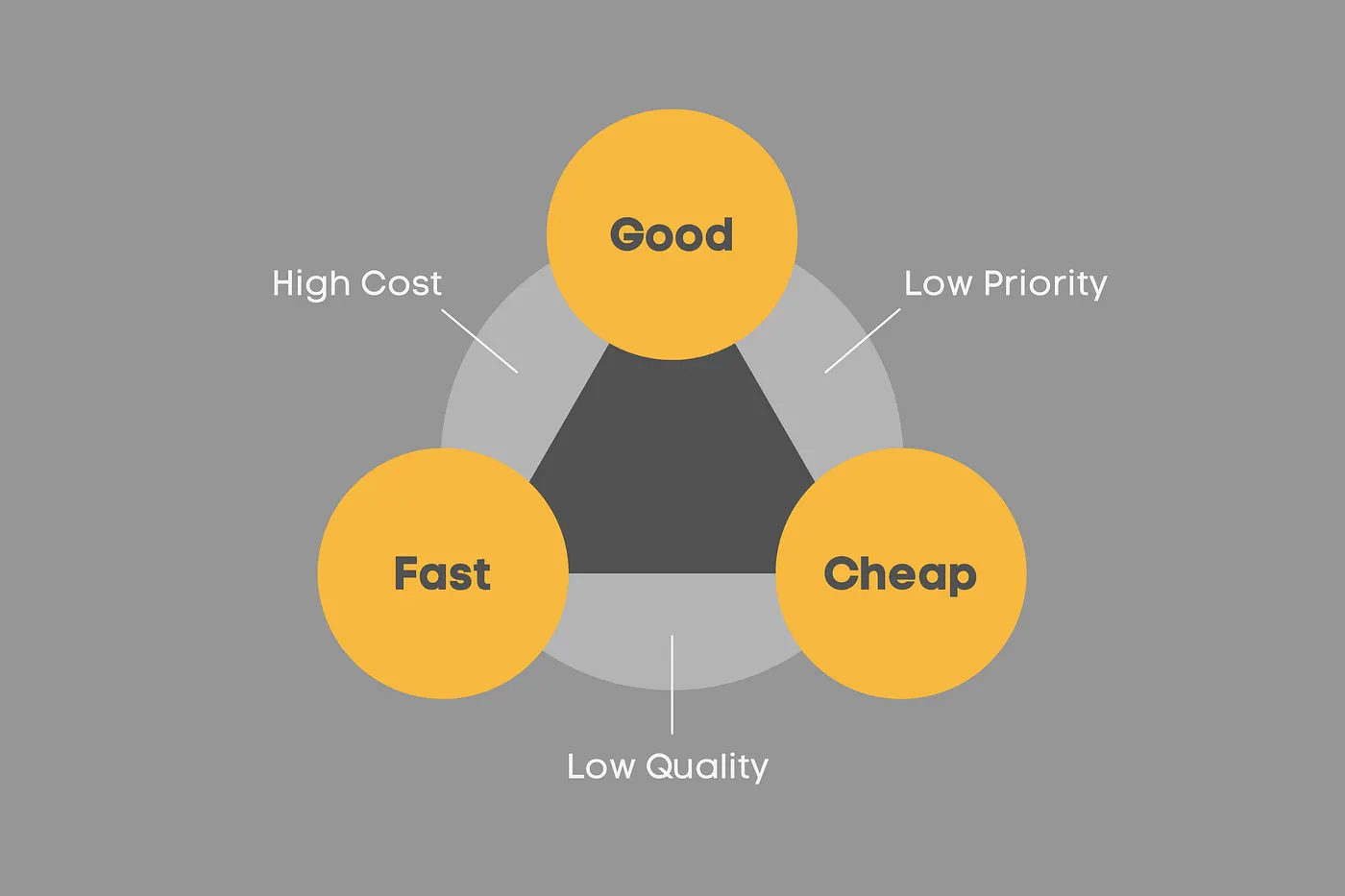
When a team is under deadline pressure and budget scrutiny, fast and cheap tend to hold. Quality, and the processes that protect it, is the corner that gives. QA isn’t cut because anyone decides quality doesn’t matter. It’s cut because in the moment, it looks like the most movable thing. With better tooling providing cover, it’s never been easier to make that call feel justified.
The AI acceleration
What AI does is give people a shinier, more confident-sounding version of the same justification. That confidence isn’t entirely misplaced. Unlike deterministic automated tests, AI can notice things that it wasn’t explicitly asked to look for. It can flag unusual patterns, question an edge case, or surface a risk the developer didn’t anticipate. That’s genuinely useful.
But there’s a difference between noticing something and understanding whether it matters to a real user in a real context. That distinction requires judgement grounded in how your product works, who uses it, and what they expect. No tool currently provides that discretion.
But look at what’s actually happening in that picture: machines generating code, machines checking it, and no human in the loop whose job is to be a guardrail and ask whether any of it actually works in the world. It’s not that the tools are bad. It’s that the loop is closed and nobody tends to notice until something leaks out of it, usually through a user and not a test.
And here’s the thing… the faster you ship more volume of code, the more surface area you’re creating for things to break. Speed doesn’t reduce risk. It just compresses the timeline between “we made a change” and “that change is in front of users.” A QA process isn’t a bottleneck to shipping, it’s the thing that keeps fast shipping from becoming a liability.
QA isn’t what most people think it is
When people hear “QA,” they often picture someone clicking through an app, filling out forms, and filing a bug ticket about a misaligned button or change in Acceptance Criteria. That can be useful, but it is a narrow view.
QA, done well, is structured thinking about what could go wrong.
It’s asking: what did we assume about how users will use this? What edge cases didn’t we consider? What happens if someone does something we didn’t expect? What did this change touch that we forgot to check?
Without a QA process, optimism is the only thing standing between your release and your users. That’s not the same as the assurance your team gets from a method and a system designed to find and resolve these trust-breaking issues before your users do.
No tool does this automatically. An AI assistant can catch a lot of things, but it can’t replace the deliberate act of someone asking “did we check everything we should have checked?” That’s a human responsibility. It requires judgment, context about what the product is supposed to do, and an understanding of how real users actually behave, which as we all know, is almost never the way you’d expect. The “you’re holding it wrong” response to the iPhone 4 antenna problem in 2010 is a useful example of this. A product shipped with confidence, an edge case missed, and the assumption that users would behave as expected turning out to be wrong.
The same pattern, different teams
I’ve seen this pattern more than once. A small, smart team moving fast. Nobody being reckless, an obvious care about quality. They just haven’t built any structure around ensuring it. No test plans. No documented coverage. No real answer to “how do we know this is ready?” beyond “we looked at it and it seemed fine.”
The outcome was predictable in hindsight: things slipped through. Not constantly, not catastrophically, but enough to matter. The damage tends to come in two forms. The first is operational — something that should have happened simply didn’t, and by the time anyone noticed, the opportunity to address it had already passed. The second is harder to measure but arguably more costly — the quiet erosion of user trust. People rarely tell you when they lose confidence in a product. They just silently stop using it.
On one project, an email opt-in flow was silently calling the wrong endpoint. From the outside, everything appeared to be working as intended. The app behaved correctly, the user saw exactly what they expected to see, but nobody who went through that flow actually got opted in. There wasn’t an error or an alert, there was nothing to indicate that something had gone wrong. It only came to light when someone thought to check whether the outcome matched the intention, rather than whether the code had executed without errors. One bug, both kinds of damage.
What changed when QA got introduced wasn’t magic. It started small — test plans before releases, a checklist of what to verify, someone explicitly responsible for stepping back and using the product the way a user would, not a developer. I wasn’t coming in as a QA purist. I just started asking the questions that nobody had a clear answer to:
- Where do our requirements actually live?
- When was the last time we walked through a full user flow from beginning to end?
- Do we know the full scope of what’s being released?
- Is there anything we haven’t said out loud yet that we’re just hoping won’t be a problem?
None of those are trick questions. But not having answers to them is an early predictor of lost user trust and operational damage. From there, we made some practical changes — small enough to do immediately, visible enough to matter. PR approvers were now expected to leave evidence that they’d looked at the feature as a whole, not just reviewed the code. Developers were expected to include validation steps in their PR description, which had a quiet but important effect: it forced them to think about how a real user would interact with what they’d built before they handed it off.
The results were real. Bugs were caught before users saw them. The team started thinking about releases differently. There was actual visibility into what was going out the door, and assurance that it had been tested beyond the scope of a PR approval. But the biggest shift was cultural — quality stopped being one person’s job and became something the whole team thought about. When there’s no QA process, quality is kind of everyone’s responsibility and kind of no one’s. Adding structure makes it concrete.
The things QA catches that nothing else does
There’s a category of problems that automated tools are genuinely bad at finding, the gap between what was built and how users actually behave.
Developers build features for a known set of use cases. They test the happy path. They check the edge cases they thought of. But users are creative in ways you can’t fully anticipate. They skip steps. They use features in combinations nobody planned for. They come to your product with different context, different devices, different expectations.
Real, exploratory QA is what catches this stuff. Not because a QA engineer is smarter than the developers, but because they’re looking at the product through a completely different lens. A developer asks “does this work the way I built it?” A QA engineer asks “does this work the way someone will actually use it?”
Then there are regressions. This is the one that gets teams over and over again. You ship something new, and it quietly breaks something old. The answer isn’t testing everything on every release, but instead having someone who understands what a change might affect and makes sure those areas get checked. Automated tests and code review help. But neither of them asks “what else could this have touched?” That question needs a person.
You don’t need a QA team to have QA
The good news for small teams: QA is a practice, not a headcount.
You don’t necessarily need to hire a dedicated QA engineer to get started, though it is a proven way to ensure that true quality assurance is achieved. That said, having someone whose entire focus is ensuring the product works the way users expect it to, rather than building or shipping it, is the most relable way to close the gap between what your process checks and waht your users actually experience. What you need is a process- some intentional, structured way of checking your work before it goes out. That could look like:
- A test plan template you fill out before any significant release
- A pre-release checklist of critical flows to verify
- A “bug bash” before major launches — 30 minutes where the whole team tests outside their own work.
- Rotating responsibility so someone other than the developer who built a feature is the one verifying it
None of these require a massive investment. What they require is the discipline to do them even when you’re in a hurry, even when it feels like everything is probably fine.
The optimism trap
The teams that drop QA almost always do it when they feel most confident. That’s exactly when it matters most. The cost savings land on a spreadsheet the same week the decision is made. The hidden cost accumulates silently, in the space between what your tests check and what your users actually do.
The tools we use to build software are going to keep getting better. AI coding assistants, automated testing, smarter CI pipelines… all of it will improve, and it’ll make a lot of things easier, and easier is good.
But there’s a distinction worth holding onto. When an AI tool marks something as done, it means the task completed, not that it’s user-ready. Those have never been the same thing. “Easier to build” and “guaranteed to work” are different things, and the gap between them is exactly where QA lives.
The benefits of faster shipping are real, the risks are as well — and they scale together. The question we need to ask before every release is “Have you done the work to be genuinely assured it works for your users, not just optimistic that it probably does?”
That question doesn’t go away. It just gets easier to ignore when you’re moving fast and feeling optimistic.
The optimism trap isn’t moving fast. It’s moving fast and assuming that’s enough.


